|
|
Oracle Coherence Monitor
User Guide |
|
|
Using the Monitor
- Administration
These displays allow you
to manage your metrics, alerts, nodes and caches. Some of these displays may be
read-only depending on your login.
-
Management Settings
OCM information about Coherence JMX management settings. -
Metrics
Administration
OCM information on metrics acquisition. Permits user to reset system metrics. -
Alert
Administration
Set thresholds for and enable alerts that have been defined in the system. -
Node
Administration
Permits user to modify node parameters. -
Cache Administration
Permits user to modify cache parameters.
NOTE: Click the
![]() button to view
the current display in a new window.
button to view
the current display in a new window.
Management Settings
This display is read-only unless you are logged in as admin or super.
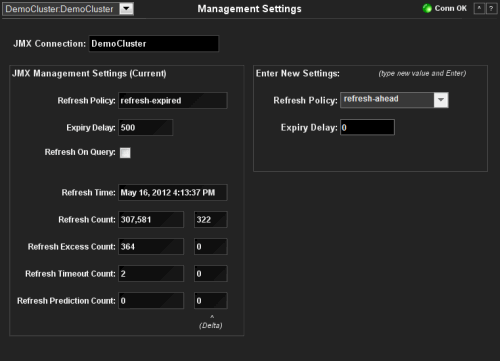
| Cluster | Select a cluster from the drop-down menu. | ||
| JMX Connection | The name of the JMX connection used to access the cluster data. | ||
| JMX Management Settings | Refresh Policy | Select a refresh policy from the drop-down list. | |
| refresh-expired |
Each MBean will be refreshed from the remote node when it is accessed and
the expiry delay has passed from the last refresh (same functionality as in pre-3.4 Coherence releases.
This option is the default setting and is best used when MBeans are accessed in a random pattern. |
||
| refresh-ahead |
MBeans are refreshed before they are requested based on prior usage patterns
after the expiry delay has passed, reducing latency of management information with a minor increase in network consumption.
This option is best when MBeans are accessed in a repetitive/programmatic pattern. |
||
| refresh-behind | Each MBean will be refreshed after the data is accessed, ensuring optimal response time. However, note that the information returned will be offset by the last refresh time. | ||
| refresh-onquery | Select this option if the refresh-on-query MBeanServer is configured. | ||
| Expiry Delay | Duration (in milliseconds) that the MBeanServer will keep a remote model snapshot before refreshing. | ||
| Refresh on Query | Specifies whether or not the refresh-on-query MBeanServer is configured. If so, then set the RefreshPolicy to refresh-onquery. | ||
| Refresh Time | The timestamp when this model was last retrieved from a corresponding node. For local servers it is the local time. | ||
| Refresh Count* | The total number of snapshots retrieved since the statistics were last reset. | ||
| Refresh Excess Count* | The number of times the MBean server predictively refreshed information and the information was not accessed. | ||
| Refresh Timeout Count* | The number of times this management node has timed out while attempting to refresh remote MBean attributes. | ||
| Refresh Prediction Count* | The number of times the MBeanServer used a predictive (refresh-behind, refresh-ahead, refresh-onquery) algorithm to refresh MBean information. | ||
*Delta values show the change in the counts within the most recent JMX retrieval period.
Metrics Administration
This display allows various
statistics to be reset, so that cumulative data can be visualized more
meaningfully. It is read-only unless you are logged in as admin or super.
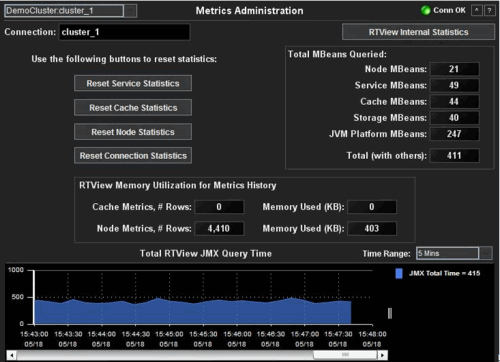
| Cluster | Select a cluster from the drop-down menu. | ||
| Connection | The name of the JMX connection used to access the cluster data. | ||
| Reset Service Statistics | Click to reset the cumulative counts of the service statistics. | ||
| Reset Cache Statistics | Click to reset the cumulative counts of the cache statistics. | ||
| Reset Node Statistics | Click to reset the cumulative counts of the node statistics. | ||
| Reset Connection Statistics | Click to reset the cumulative counts of the connection statistics. | ||
| Total MBeans Queried | Node MBeans | Total number of node MBeans queried. | |
| Service MBeans | Total number of service MBeans queried. | ||
| Cache MBeans | Total number of cache MBeans queried. | ||
| Storage MBeans | Total number of storage MBeans queried. | ||
| JVM Platform MBeans | Total number of JVM platform MBeans queried. | ||
| Total | Total number of MBeans queried. | ||
| RTView Memory Utilization for Metrics History | By default, the Oracle Coherence Monitor stores several hours of data using in-memory tables. | ||
| Cache Metrics, # Rows | The number of table rows used by the OC Monitor to store cache metrics data. | ||
| Cache Metrics, Memory Used (KB) | The amount of memory (KB) used by the OC Monitor to store cache metrics data. | ||
| Node Metrics, # Rows | The number of table rows used by the OC Monitor to store node metrics data. | ||
| Node Metrics, Memory Used (KB) | The amount of memory (KB) used by the OC Monitor to store node metrics data. | ||
| Total RTView JMX Query Time | Total amount of time, in milliseconds, to query the monitoring MBeans from Coherence. | ||
| Time Range | Select a time range varying from 2 Minutes to Last 7 Days, or display All Data. | ||
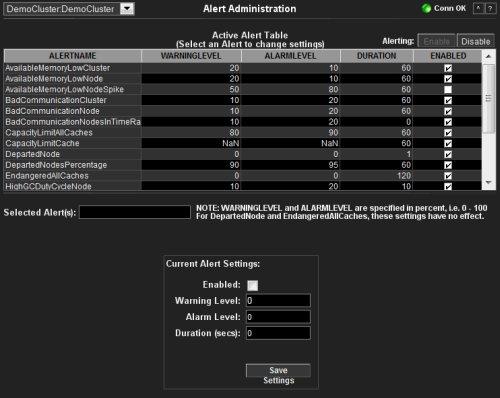
Alert Administration
Use this display
to configure alert thresholds, and enable or disable alerts.
Alert thresholds are applied globally across all clusters in an OCM instance (to
have separately defined alert thresholds for a cluster, a separate OCM instance
must be installed for the cluster).
Alerting is enabled by default. This display
is read-only unless you are logged in as admin or
super.
To configure thresholds or enable/disable alerts, you configure the Alert Type (also referred to as the Alert Name) such as AvailableMemoryLowNodeSpike. A single alert type is applied to multiple sources--nodes or caches--depending on the kind of alert type. Alert types issue alerts for any source in the cluster that exceeds the specified thresholds for the alert type. Each alert issued contains a unique identifier for the source that indicates the alert origin.
For example, the AvailableMemoryLowNodeSpike alert type applies to all nodes in the cluster, therefore the AvailableMemoryLowNodeSpike threshold settings are the same for all nodes in the cluster. When the AvailableMemoryLowNodeSpike alert type is disabled, no AvailableMemoryLowNodeSpike alerts are issued for any node in the cluster. When the AvailableMemoryLowNodeSpike alert type is enabled, AvailableMemoryLowNodeSpike alerts are issued for any node in the cluster that exceeds a threshold specified for the AvailableMemoryLowNodeSpike alert type. Each alert issued by the AvailableMemoryLowNodeSpike alert type contains the unique identifier for the source node.
Likewise, the EndangeredAllCaches alert type applies to all caches in the cluster, therefore the EndangeredAllCaches threshold settings are the same for all caches in the cluster. When the EndangeredAllCaches alert type is disabled, no EndangeredAllCaches alerts are issued for any cache in the cluster. When the EndangeredAllCaches alert type is enabled, EndangeredAllCaches alerts are issued for any cache in the cluster that exceeds a threshold specified for the EndangeredAllCaches alert type. Each issued alert contains the unique identifier for the source cache.
Enabling / Disabling Alerts
There are two ways to enable and disable alerting. You can enable / disable all
alert types (the alerting system), or a single
alert type.
- To enable / disable
the alerting system: Use
 . When disabled,
all
alerting is suspended and
the
Alert Detail Table
displays the following message:
. When disabled,
all
alerting is suspended and
the
Alert Detail Table
displays the following message:
 Alerting is currently disabled.
When you enable alerting, the
message disappears.
Alerting is currently disabled.
When you enable alerting, the
message disappears. - To enable / disable a
single alert type:
Select an alert name in
the Active Alert Table (the selected alert name is shown in the
Selected Alert field), click the
Enabled
 checkbox
under Current Alert Settings, then click Save Settings. The
Enabled
checkbox in
the Active Alert Table column
is updated for the alert type.
checkbox
under Current Alert Settings, then click Save Settings. The
Enabled
checkbox in
the Active Alert Table column
is updated for the alert type.

Currently active alerts are shown in the Alert Views displays.
NOTE: Tabular alerts allow you to configure alert types per individual caches. For details, see Tabular Alerts.
| Cluster | Select a cluster from the drop-down menu. | ||||
|
Alerting
|
Use
the toggle buttons
to enable or disable the alerting system. Alerting is enabled by default.
NOTE: To enable or disable a
single alert, select an alert name in
the Active Alert Table (the selected alert name is shown in the
Selected Alert field), click the
Enabled
|
||||
| Enable | Select
to enable all alerting. Alerting is enabled by default.
When you enable alerting, the
|
||||
| Disable | Select
to disable all alerting. When disabled, all
alert types are suspended from issuing alerts and
the
Alert Detail Table
displays the following message:
|
||||
| Active Alert Table |
Lists all available alert types and their
current configurations. Configure alert thresholds, enable or disable
alerts. NOTE: Not all alerts are currently implemented and will be implemented in an upcoming release. |
||||
|
Alert
Name
|
The alert type. A single alert type is applied to multiple sources (nodes or caches). You configure alert thresholds on alert types. For example, the AvailableMemoryLowNodeSpike alert type applies to multiple nodes. The CapacityLimitCache alert type applies to multiple caches. | ||||
| AvailableMemory-LowCluster | A single alert is executed if the average percent memory used over max memory of all nodes in the cluster exceeds the specified thresholds. | ||||
| AvailableMemory-LowNode | For each node in the cluster, an alert is executed if the percent memory used over max memory available for that node exceeds the specified thresholds. | ||||
| AvailableMemory-LowNodeSpike | For
each node in the cluster, an alert is executed if the percent memory used
exceeds the specified threshold for the percent above average memory used in
the previous 24 hours. For example, if the threshold is set to 50% of total
memory used, and the average memory consumption on a particular node for the
previous 24 hours is 40%, an alert will be executed if current memory usage
exceeds 60% of the total. NOTE: The 24 hour time span (86400 seconds) is controlled by the $AVERAGE_MEMORY_TIME_WINDOW substitution. The warning
default setting is
115 (percent) of the previous 24 hours and the alarm
default setting is 125 (percent) of the previous 24 hours. |
||||
| BadCommunication-Cluster | A single alert is executed if the average communication failure rate of all nodes in the cluster drops below the specified thresholds. | ||||
| BadCommunication-Node | For each node in the cluster, an alert is executed if the communication failure rate for that node drops below the specified thresholds. | ||||
| BadCommunication-NodesInTimeRange |
Executes a single warning and a single
alert if the percentage of nodes in a cluster meets or exceeds the specified threshold for the
BadCommunicationNode alert within a time range specified.
To specify the time range, modify the
$BAD_COMMUNICATION_NODES_TIME_RANGE The default time range setting is 5 minutes (300 seconds), the warning default setting is 40 (percent) and the alarm default setting is 50 (percent). By default the alert is enabled. |
||||
| CapacityLimit-AllCaches |
An
alert is executed if the percent cache used over cache capacity for any
cache in the cluster exceeds the specified thresholds. There is one
highWarning and one highAlert threshold. For example, if there are 3 caches
in a cluster, where:
cache1 val = 95 and the CapacityLimitAllCaches highWarning is 80 and highAlert is 90, one high alert is executed. |
||||
| CapacityLimit-Cache |
This
tabular alert
executes an alert for each cache in the cluster where the percent
cache used over cache capacity exceeds the specified thresholds. There
is one highWarning and one highAlert threshold per cache. For
example, if there are 3 caches in a cluster, where:
cache1 val = 95 and the CapacityLimitAllCaches highWarning is 80 and highAlert is 90, two high alerts are executed, one for cache1 and another for cache2. |
||||
| DepartedNode | For each node in the cluster, an alert is executed if the time a node is absent from the cluster exceeds the specified thresholds. When the departed node rejoins the cluster, the alert is cleared. | ||||
| DepartedNodes-Percentage | This
scalar alert executes a single warning and a single alert if the percentage
of nodes departed from the cluster exceeds the specified threshold within the specified time period. The percentage is measured against the
total number of nodes in the cluster, including both running and departed
nodes. The time period is set in the OPTIONS.ini file using the $NODES_DEPARTED_TIME_WINDOW substitution. The time period can also be overridden using the command line interface. For example, the following sets a time window of 300 seconds: -sub:$NODES_DEPARTED_TIME_WINDOW:300 The time period default setting is 600 (10 minutes), the warning default setting is 90 (percent) and the alarm default setting is 95 (percent). By default the alert is disabled. |
||||
| Endangered-AllCaches | This alert is executed if the StatusHA for the cache service is NODE_SAFE (high warning) or ENDANGERED (high alert). | ||||
| HighPending-RequestNode |
A single alert is
executed if the RequestPendingCount
amount exceeds the specified threshold. This alert allows for setting the
warning level, alarm level and duration.
By default the alert is disabled. |
||||
| HighGCDuty-CycleNode | This
scalar alert executes a single warning and a single alert if a node exceeds
the specified duty cycle threshold (the percent of time spent in Garbage
Collection). By default the alert is enabled with the following default settings: Warning is 10 (percent), Alarm is 20 (percent) and Duration is 10 seconds. |
||||
| HighTask-BacklogNode | A
single warning and a single alert are executed if the number of backlogged
tasks exceeds the specified user threshold. This alert allows for setting
the warning level, alarm level and duration.
The default setting executes a warning if the number of backlogged tasks exceeds 10, and executes an alert if the number of backlogged tasks exceeds 20. By default the alert is disabled. |
||||
| HighThread-AbandonedNode | A
single alert is executed if the Coherence Thread Abandoned Count amount
exceeds the specified threshold. This alert allows for setting the warning
level, alarm level and duration. The default setting executes a warning and an alert if the Thread Abandoned Count amount exceeds 0. The default duration setting is 60. By default the alert is enabled. |
||||
|
LongGCDuration-Node
|
A single warning and a single
alert are executed if any of the last
garbage collection times exceed the specified duration.
The default setting executes a warning if the duration exceeds 1 second, and executes an alert if the duration exceeds 2 seconds. It is possible for GC times to exceed the specified duration and NOT execute an alert. This is possible if it occurs between the alert duration time and an alert condition time. For example, if your alert duration is 60 seconds, and there is also an alert condition set at 27 seconds into that 60 seconds, the following scenarios could occur (where XX:XX:XX is Hours:Minutes:Seconds):
Scenario
1: 12:00:27 GC amount exceeds the specified threshold. Alert ignored for now. 12:01:00 GC amount is below the specified threshold. No alert executed.
Scenario
2: 12:00:27 GC amount exceeds the specified threshold. Alert ignored for now. 12:01:00 GC amount remains above the specified threshold. Alert executed. By default the alert is enabled. |
||||
|
ObjectCountDelta-UpCache
|
This
tabular alert
executes
a single warning and a single
alert for each cache in the cluster if the cache
object count delta increases and reaches the specified threshold. In
addition to setting the warning and alarm levels, this
alert also allows for setting the duration
for each cache. When this alert is selected in the Active Alert Table, the Per Cache Alert Setting box is displayed (rather than the scalar alert box). By default the alert is disabled. |
||||
| ObjectCountDelta-DownCache |
This
tabular alert
executes a single warning and a single
alert for each cache in the cluster where
the cache object count delta decreases and
reaches the specified threshold. In addition to setting the warning and
alarm levels, this
alert also allows for setting the duration
for each cache. When this alert is selected in the Active Alert Table, the Per Cache Alert Setting box is displayed (rather than the scalar alert box). By default the alert is disabled. |
||||
| WARNINGLEVEL | Set the threshold at which you want a high warning alert to be executed. NOTE: This does not apply to CapacityLimitCache. | ||||
| ALARMLEVEL | Set the threshold at which you want a high alert to be executed. NOTE: This does not apply to CapacityLimitCache. | ||||
| DURATION | Set the amount of time (in seconds) that the value must be above the specified Warning Level or Alert Level threshold before an alert is executed. Enter 0 for immediate execution. | ||||
| ENABLED | Select
the
NOTE:
To enable / disable
the alerting system, use
the
|
||||
| Selected Alert(s) | Lists the alert(s) selected in the table. | ||||
| Current Alert Settings (apply to alert as a whole) | Enabled | Select to enable the selected alert(s) as a whole. | |||
| Warning Level | Set the warning level for the selected alert(s) as a whole. | ||||
| Alarm Level | Set the warning level for the selected alert(s) as a whole. | ||||
| Duration (secs) | Set the amount of time (in seconds) that the value for the selected alerts(s) must be above the specified Warning Level or Alert Level threshold before an alert is executed. Enter 0 for immediate execution. | ||||
| Save Settings | Click to apply alert settings if modified. | ||||
Tabular alerts allow you to specify the warning level, alarm level, duration and enabled flag settings for individual caches. Examples of tabular alerts are CapacityLimitCache, ObjectCountDeltaUpCache and ObjectCountDeltaDownCache. Tabular alerts are read-only unless you are logged in as an administrator or super user. By default, tabular alerts are disabled.
To configure a tabular alert, navigate to the Alert Administration display and select a tabular alert from the Active Alert Table. This opens and populates the Per Cache Alert Settings table (see below). Verify that the Enabled checkbox under Current Alert Settings is selected. Click on one or more caches to select the desired caches. Adjust the Warning Level, Alarm Level and Enabled fields, and click Save Settings to apply and save the settings to the alert database. To remove settings for caches from the alert database, select one or more caches in the table and click Remove Settings. This removes the settings for the selected cache(s).
NOTE: The Enabled and Duration columns in the Active Alert Table apply to the tabular alert as a whole. For example, if Enabled is deselected for the CapacityLimitCache alert type in the Active Alert Table, the tabular alert type is disabled and no CapacityLimitCache alerts are generated for any of the caches.
Current alerts are shown in the Alert Views display and the Caches / Nodes / Alerts display.
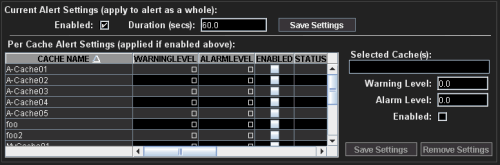
| Current Alert Settings (apply to alert as a whole): | The current settings for the selected tabular alert type. The settings for this alert type are applied to all caches unless you configure different settings for individual caches. Use the Per Cache Alert Settings table to configure cache alert settings individually. |
|
| Enabled
|
Select
to enable the selected alert type.
When enabled:
When
disabled,
no alerts
for the alert type
are issued for any cache in the cluster, and
the Enabled
NOTE: This must be enabled in order use the Per Cache Alert Settings table to configure cache alert settings individually. |
|
| Duration (secs): | Set the amount of time (in seconds) that the value must be above the specified Warning Level or Alert Level threshold before an alert is issued. Enter 0 for immediate execution. | |
| Save Settings | Click to apply alert settings if modified. | |
|
Per Cache Alert
Settings (applied if enabled above):
|
The table lists all available caches in the cluster, their threshold settings and their status. Configure alert settings for individual caches. Select a cache, enter the warning and alarm levels, select Enabled, then click Save Settings. Verify your settings in the Per Cache Alert Settings table. saved indicates the settings are saved to the alert database. | |
| Cache Name | The name of the cache. | |
| Warning Level | Set the threshold at which you want a high warning alert issued for the cache. | |
| Alarm Level | Set the threshold at which you want a high alert issued for the cache. | |
| Enabled | Click to enable the alert for the cache. | |
| Status |
The state of the
alert settings for the cache. Valid values are: saved - The settings have been applied and saved to the alert database. blank - No settings have been applied or saved for the cache. absent - Settings have been saved for a cache that is not active. |
|
| Full Cache Name | The full name of the cache. | |
| Save Settings | Click to apply and save per cache alert settings to the alert database. | |
| Remove Settings | Click to remove per cache alert settings from the alert database. | |
Node Administration
This display allows the user to view
and change settings for individual Nodes. It is read-only unless you are logged
in as super. Click on the desired Node to
select that Node. Change the data item in the bottom half of the display and
press Return to make the change. All data on this display is queried from and
set on the Coherence ClusterNodeMBean.
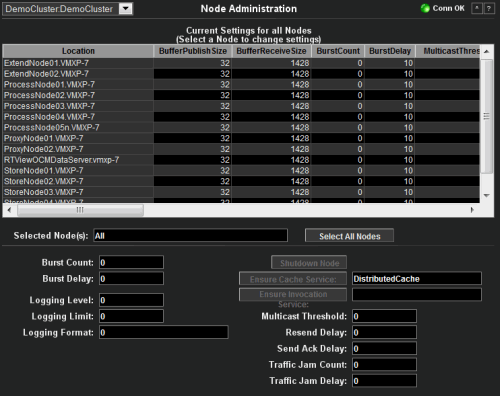
| Cluster | Select a cluster from the drop-down menu. | |
| Current Settings for All Nodes | Location | A unique identifier for each node. It is defined as: member_name.machine.rack.site. |
| BufferPublishSize | The buffer size of the unicast datagram socket used by the Publisher, measured in the number of packets. Changing this value at runtime is an inherently unsafe operation that will pause all network communications and may result in the termination of all cluster services. | |
| BufferReceiveSize | The buffer size of the unicast datagram socket used by the Receiver, measured in the number of packets. Changing this value at runtime is an inherently unsafe operation that will pause all network communications and may result in the termination of all cluster services. | |
| BurstCount | The maximum number of packets to send without pausing. Anything less than one (e.g. zero) means no limit. | |
| BurstDelay | The number of milliseconds to pause between bursts. Anything less than one (e.g. zero) is treated as one millisecond. | |
| MulticastThreshold | The percentage (0 to 100) of the servers in the cluster that a packet will be sent to, above which the packet will be multicasted and below which it will be unicasted. | |
| ResendDelay | The minimum number of milliseconds that a packet will remain queued in the Publisher`s re-send queue before it is resent to the recipient(s) if the packet has not been acknowledged. Setting this value too low can overflow the network with unnecessary repetitions. Setting the value too high can increase the overall latency by delaying the re-sends of dropped packets. Additionally, change of this value may need to be accompanied by a change in SendAckDelay value. | |
| SendAckDelay | The minimum number of milliseconds between the queueing of an Ack packet and the sending of the same. This value should be not more then a half of the ResendDelay value | |
| TrafficJamCount | The maximum total number of packets in the send and resend queues that forces the publisher to pause client threads. Zero means no limit. | |
| TrafficJamDelay | The number of milliseconds to pause client threads when a traffic jam condition has been reached. Anything less than one (e.g. zero) is treated as one millisecond. | |
| LoggingLevel | Specifies which logged messages will be output to the log destination. Valid values are non-negative integers or -1 to disable all logger output. | |
| LoggingLimit | The maximum number of characters that the logger daemon will process from the message queue before discarding all remaining messages in the queue. Valid values are integers in the range [0...]. Zero implies no limit. | |
| LoggingFormat | Specifies how messages will be formatted before being passed to the log destination | |
| LoggingDestination | The output device used by the logging system. Valid values are stdout, stderr, jdk, log4j, or a file name. | |
| nodeld | The short Member id that uniquely identifies the Member at this point in time and does not change for the life of this Member. | |
| ProcessName | A configured name that should be the same for Members that are in the same process (JVM), and different for Members that are in different processes. If not explicitly provided, for processes running with JRE 1.5 or higher the name will be calculated internally as the Name attribute of the system RuntimeMXBean, which normally represents the process identifier (PID). | |
| Selected Node(s) | Lists the nodes selected in the table. | |
| Select All Nodes | Click to select all nodes. | |
| Shutdown Node | Stop all the clustered services running at this node (controlled shutdown). The management of this node will node be available until the node is restarted (manually or programmatically). | |
| Ensure Cache Service | Ensure that a CacheService for the specified cache runs at the cluster node represented by this MBean. This method will use the configurable cache factory to find out which cache service to start if necessary. Return value indicates the service name; null if a match could not be found. | |
| Ensure Invocation | Ensure that an InvocationService with the specified name runs at the cluster node represented by this MBean. | |
Cache Administration
This
display allows the user to view
and change settings for individual caches. It is read-only unless you are logged
in as super. Click on the desired cache to
select that cache. Change the data item in the bottom half of the display and
press Return to make the change. The data on this display is queried from and
set on the Coherence CacheMBean.
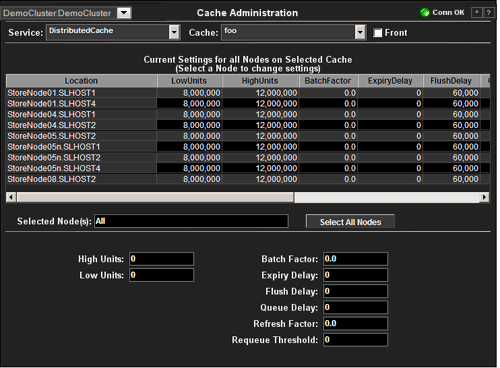
| Cluster | Select a cluster from the drop-down menu. | |
| Service | Select the service to display. | |
| Cache | Select the cache to display. | |
| Front | Select for front tier, deselect for back tier. | |
| Current Settings for all Nodes on Selected Cache | Location | A unique identifier for each node. It is defined as: member_name.machine.rack.site. |
| LowUnits | The number of units to which the cache will shrink when it prunes. This is often referred to as a `low water mark` of the cache. | |
| HighUnits | The limit of the cache size measured in units. The cache will prune itself automatically once it reaches its maximum unit level. This is often referred to as the `high water mark` of the cache. | |
| BatchFactor | The BatchFactor attribute is used to calculate the `soft-ripe` time for write-behind queue entries. A queue entry is considered to be `ripe` for a write operation if it has been in the write-behind queue for no less than the QueueDelay interval. The `soft-ripe` time is the point in time prior to the actual `ripe` time after which an entry will be included in a batched asynchronous write operation to the CacheStore (along with all other `ripe` and `soft-ripe` entries). This attribute is only applicable if asynchronous writes are enabled (i.e. the value of the QueueDelay attribute is greater than zero) and the CacheStore implements the storeAll() method. The value of the element is expressed as a percentage of the QueueDelay interval. Valid values are doubles in the interval [0.0, 1.0]. | |
| ExpiryFactor | The time-to-live for cache entries in milliseconds. Value of zero indicates that the automatic expiry is disabled. Change of this attribute will not affect already-scheduled expiry of existing entries. | |
| FlushDelay | The number of milliseconds between cache flushes. Value of zero indicates that the cache will never flush. | |
| QueueDelay | The number of seconds that an entry added to a write-behind queue will sit in the queue before being stored via a CacheStore. Applicable only for WRITE-BEHIND persistence type. | |
| RefreshFactor | The RefreshFactor attribute is used to calculate the `soft-expiration` time for cache entries. Soft-expiration is the point in time prior to the actual expiration after which any access request for an entry will schedule an asynchronous load request for the entry. This attribute is only applicable for a ReadWriteBackingMap which has an internal LocalCache with scheduled automatic expiration. The value of this element is expressed as a percentage of the internal LocalCache expiration interval. Valid values are doubles in the interval[0.0, 1.0]. If zero, refresh-ahead scheduling will be disabled. | |
| Requeue Threshold | The maximum size of the write-behind queue for which failed CacheStore write operations are requeued. If zero, the write-behind requeueing will be disabled. Applicable only for WRITE-BEHIND persistence type. | |
| nodeld | The node ID. | |
| Selected Node(s) | Lists the nodes selected in the table. | |
| Select All Nodes | Click to select all nodes in the table. | |
|
RTView contains components licensed under the Apache
License Version 2.0. |
|
Treemap Algorithms v1.0 is used without
modifications and licensed by MPL Version 1.1. Copyright © 2001 University of
Maryland, College Park, MD |
|
Datejs is licensed under MIT. Copyright © Coolite Inc. |
|
jQuery is
licensed under MIT. Copyright © John Resig, |
|
JCalendar 1.3.2 is licensed under LGPL.
Copyright © Kai Toedter. |
|
jQuery is licensed under MIT. Copyright (c) 2009 John
Resig, http://jquery.com/ JCalendar 1.3.2 is licensed under LGPL.
Copyright © Kai Toedter. |
|
JMS, JMX and Java are trademarks or registered trademarks
of Sun Microsystems, Inc. in the United States and other countries. They are
mentioned in this document for identification purposes only. |
|
SL, SL-GMS, GMS, RTView, SL Corporation, and
the SL logo are trademarks or registered trademarks of Sherrill-Lubinski
Corporation in the United States and other countries. Copyright © 1998-2011
Sherrill-Lubinski Corporation. All Rights Reserved. |